天凤牌山生成算法及其验证
本文讲解了天凤牌山生成算法以及玩家对它的验证方法,并分析了天凤在保证公开公平这方面的成功之处以及欠缺。最后把天凤和雀魂进行了对比。
只关心天凤公平不公平的话可以直接跳到“结论以及和雀魂的对比”。
文中“角田”和“天凤服务器”经常混用。
天凤牌山生成算法讲解
角田在天凤博客里以代码片段的形式公开了天凤牌山生成方法。代码似乎是C和C++的混合。代码的注释不是特别详细,而且是日文的。角田也没有用通俗的语言来解释牌山生成方法。网友“畅畅”在Ta的博客里给天凤牌山的代码加上了中文注释,并用通俗的语言总结了牌山生成的过程,但是有一些小错误。我直接引用Ta的博客里的代码,并加入一些注释。 对具体代码不感兴趣的话可以跳过。
1 | //天凤牌山生成代码 http://tenhou.net/stat/rand/ |
一局天凤麻将游戏中,生成牌山的要素: 1.
mtRoot:是一个可能以系统时间、登录名等东西进行填充,用于随机数生成算法的种子。此外,mtRoot还用来决定东南西北的座位 - mtRoot 的具体生成方式角田并没有公开,如果公开了可能可以伪造种子来知晓牌山。2.
mtLocal:用 mtRoot 生成的随机数,作为新的种子。(811注:mtRoot和mtLocal应该是随机数生成器的对象,而不是种子3.
src数组,这个数组用于用于 SHA 512 散列算法。内容是以 mtLocal 做种子,288 次随机数算法取的一长串二进制流。4.
rnd数组:长度为 144。会对 src 进行 SHA 512 散列算法,RND 是存放算法的结果的数组。之后要利用 RND 数组生成牌山。此外,每一局投的骰子也是 rnd 里面来的。 - rnd 数组的生成结果由于散列算法的性质,保证了公平性。5.
yama数组,长度 136 。就是牌山本体。思路很简单,一开始里面的数据初始化是 123456 这样的等差数列,然后对RND数组的元素进行求余后不断 swap 就可以打乱(shuffle)。获取东一局的游戏牌山需要从第1步执行到第5步,第二局(无论是东一一本场还是东二)及之后只需要执行第 3 步到第 5 步。
虽然说第三步里面有随机要素,但其实四个人进到一桌坐下来,本质上这一局的牌山都已经安排好了。
我再来总结一下流程:
- 角田的服务器生成mtRoot的种子(不公开);
- 对一场比赛,用mtRoot生成(4+624)个32bit随机数,前四个用于确定座席,后624个作为mtLocal的种子;
- 每一小局(每次配牌):
- 用mtLocal生成288个32bit随机数,共9216bit;
- 将9216bit以1024bit为单位用SHA-512 hash到4608bit = 144*32bit;
- 将144个32bit整数用于洗牌和掷骰子;
- 比赛结束后,将mtLocal的种子写入牌谱。(在角田的代码中未体现)
玩家可以进行哪些检定,以及具体检定方法
天凤公开了从mtLocal的种子生成牌山的方法(代码),并在比赛结束后在牌谱中公开了mtLocal的种子,玩家可以从牌谱文件中找出这个种子,自己算出每一小局的牌山,与天凤牌谱显示的牌山核对;
天凤在对局前公开了席顺和mtLocal的种子的SHA-512 hash,玩家可以在对局结束后从牌谱文件里找出这个种子,和席顺一起自己hash一下,和天凤对局前公开的hash核对是否相同。
具体检定方法: 1. 牌山。
打一把真人对战,获取牌谱链接。牌谱链接形如“https://tenhou.net/0/?log=xxxxxxxxgm-xxxx-xxxx-xxxxxxxx&tw=x”。把“log=”后的东西拼接到“https://tenhou.net/0/log/find.cgi?log=”后面,形成一个形如“https://tenhou.net/0/log/find.cgi?log=xxxxxxxxgm-xxxx-xxxx-xxxxxxxx&tw=x”的网址。在浏览器地址栏输入它,回车,可以下载到牌谱文件。(如果牌谱链接没有&tw=x,在后面加上&tw=0即可) 例:我们搞到了玩家“トトリ先生19歳”的一个牌谱链接http://tenhou.net/0/?log=2016100120gm-00a9-0000-fca091df。我们在浏览器地址栏输入https://tenhou.net/0/log/find.cgi?log=2016100120gm-00a9-0000-fca091df&tw=0,即可下载牌谱文件。
这个牌谱文件是gzip格式的。先解压,然后用文本编辑器打开,可以看到seed="mt19937ar-sha512-n288-base64,一大堆东西"。把那一大堆东西复制出来,进行base64解码,即可得到mtLocal的种子。(注:从某些途径获取的牌谱是plaintext而不是gz)
例:将刚刚下载的牌谱解压并使用某文本编辑器打开  我们要的“一大堆东西”找到了。把它base64解码。以Python为例
我们要的“一大堆东西”找到了。把它base64解码。以Python为例
1
2
3import base64
seed_str = 'Ov9f...Hcjm'
seed_bytes = base64.b64decode(seed_str)1
2
3result = []
for i in range(len(seed_bytes) // 4):
result.append(int.from_bytes(seed_bytes[i*4:i*4+4], byteorder='little'))
- 初始化mtRand后,我们就可以按照角田的代码,对每一小局,生成288个32bit随机数,共9216bit,再将9216bit以1024bit为单位分9次用SHA-512 hash到512bit*9 = 4608bit = 144*32bit。
1
2
3
4
5
6
7
8
9
10
11for nKyoku in range(10):
rnd = [0] * 144 # rnd将被用于洗牌和投骰子
rnd_bytes = b''
src = [random.getrandbits(32) for _ in range(288)] # 生成288个32bit随机数,赋值给src
for i in range(9): # 分9次hash
hash_source = b''
for j in range(32): # 每次hash的source的大小为32*4Byte*8bit/Byte = 1024bit
hash_source += src[i*32+j].to_bytes(4, byteorder='little')
rnd_bytes += hashlib.sha512(hash_source).digest()
for i in range(144):
rnd[i] = int.from_bytes(rnd_bytes[i*4:i*4+4], byteorder='little') # 把hash结果转换成int类型1
2
3
4
5
6# 以四麻为例。三麻把所有136替换为108
yama = [i for i in range(136)]
for i in range(136 - 1):
temp = yama[i]
yama[i] = yama[i + (rnd[i]%(136-i))]
yama[i + (rnd[i]%(136-i))] = temp
三麻:yama数组的元素的范围是[0,108)。除以4向下取整,0为1万,1为9万,2-10为1-9筒,11-19为1-9索,20-26为东南西北白发中。如果一张5p5s除以4的余数为0,且规则有赤,则为赤牌。
骰子对牌山没有影响,不投也无所谓
1
2
3
4
5# 打印牌山。依旧以四麻为例
print('nKyoku=' + str(nKyoku) + ' yama=')
haiDisp = ["1m", "2m", "3m", "4m", "5m", "6m", "7m", "8m", "9m", "1p", "2p", "3p", "4p", "5p", "6p", "7p", "8p", "9p", "1s", "2s", "3s", "4s", "5s", "6s", "7s", "8s", "9s", "东", "南", "西", "北", "白", "发", "中"]
for i in range(136):
print(haiDisp[yama[i] // 4], end=',')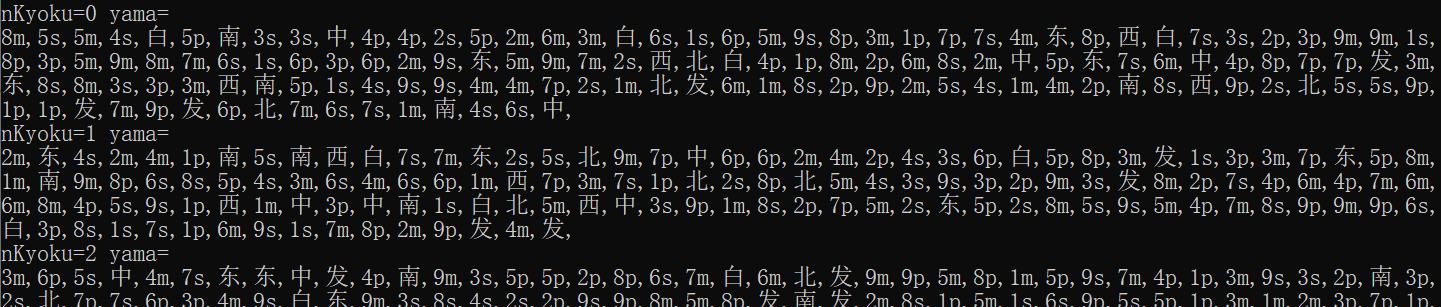 用天凤官方web版牌谱阅读器打开牌谱(https://tenhou.net/3/?log=2016100120gm-00a9-0000-fca091df),东一局牌山为
用天凤官方web版牌谱阅读器打开牌谱(https://tenhou.net/3/?log=2016100120gm-00a9-0000-fca091df),东一局牌山为
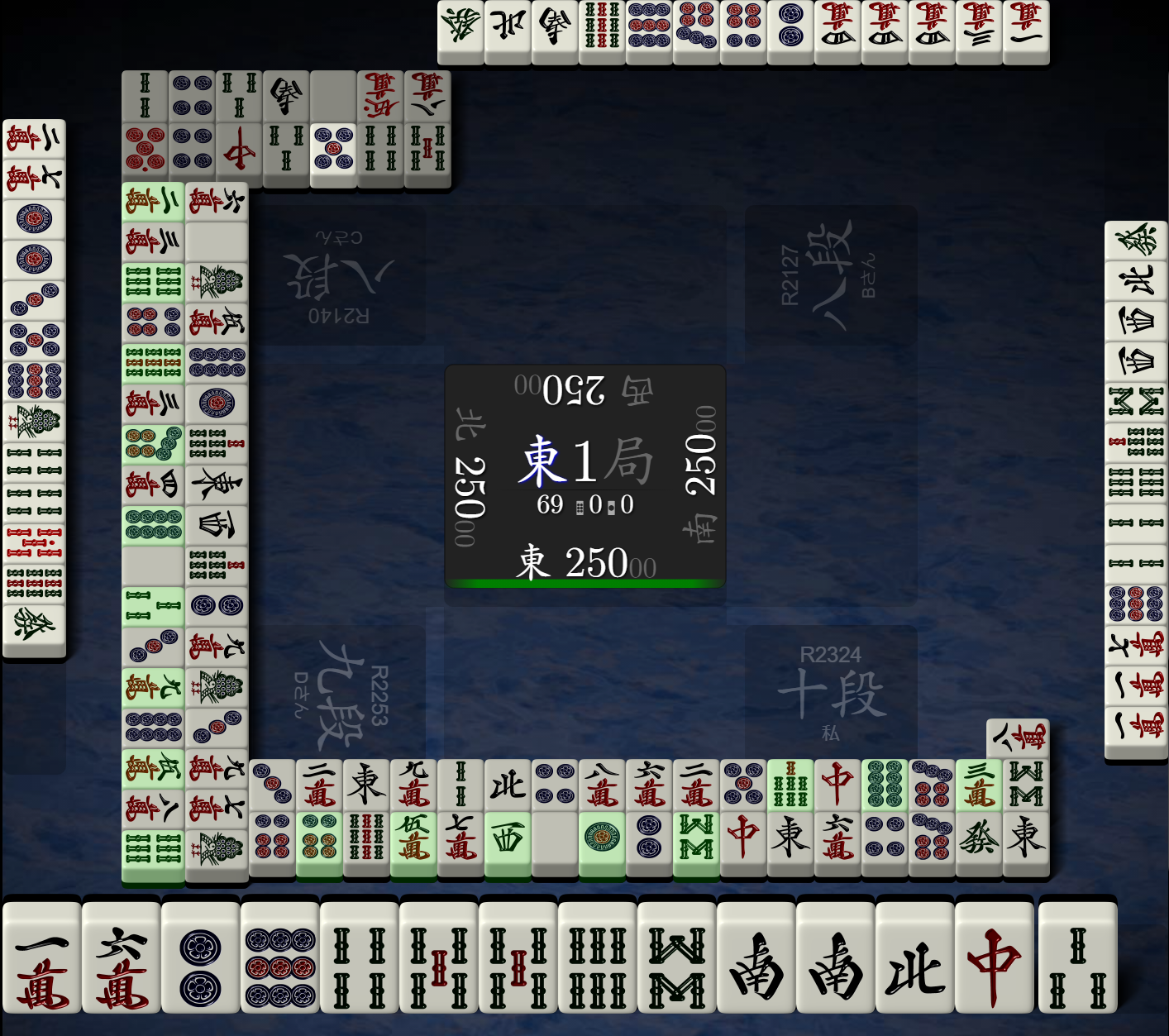 经对比,牌山一致。
经对比,牌山一致。
席顺和mtLocal的种子。
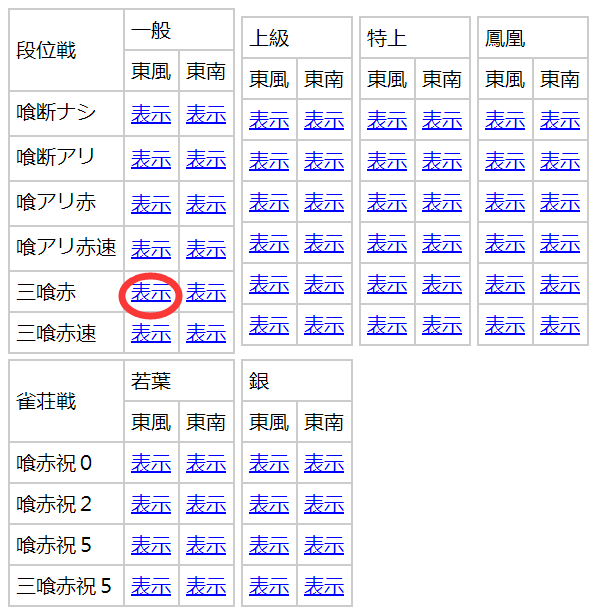
- 打一把段位。在预约之前,打开https://tenhou.net/stat/rand/,根据我们要打的规则来点击对应的“表示”。如果我们打算打“三般东喰赤”,就点击红圈圈出来的“表示”。
 会弹出一个新标签页
会弹出一个新标签页 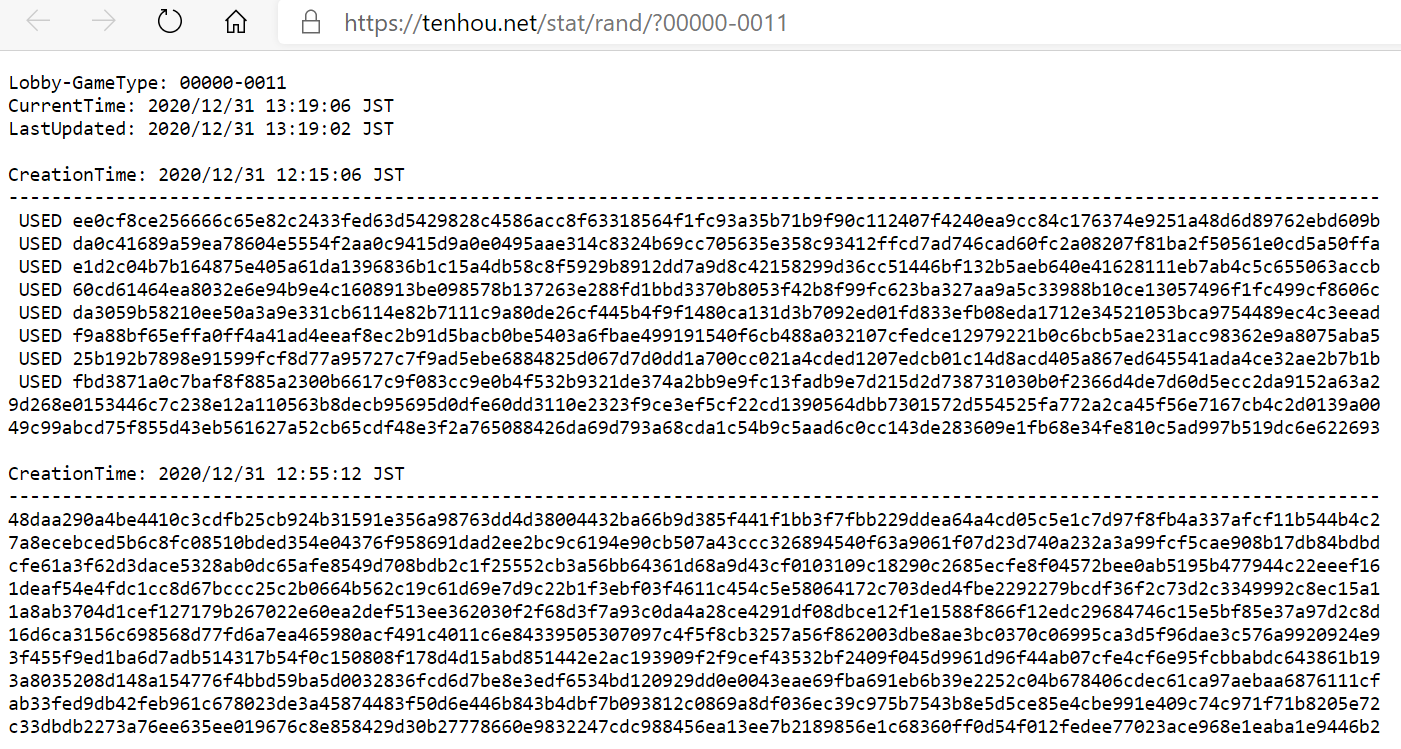 可以看到一堆字符。别关掉它。现在可以打一把段位了。
可以看到一堆字符。别关掉它。现在可以打一把段位了。
(b1) 打完后,复制牌谱链接,回到https://tenhou.net/stat/rand/,把牌谱链接粘贴到下图的框里,点击OK按钮
 然后我们可以得到一串字符
然后我们可以得到一串字符  回到打段位前“别关掉它”的标签页,发现9d26那一行字符的确存在。这说明在对局前,本场对局的种子及席顺已经确定。
回到打段位前“别关掉它”的标签页,发现9d26那一行字符的确存在。这说明在对局前,本场对局的种子及席顺已经确定。
 检定完成。
检定完成。等等,用角田的工具来计算hash,不就是让角田自己给自己当裁判了?角田自己也说:
※天鳳が提供しているCGI版の検証ツールを使用することは、厳密な検証にはなりません。
我们可以不用角田的工具,自己来计算。在https://tenhou.net/stat/rand/中角田写道 >- SHA512のソースは4(座席並べ替え情報) + 624*8(乱数種) = 4996bytes
但角田并没有说明“座席並べ替え情報”和“乱数種”是如何编码的,这导致了玩家无法自己计算hash。经与角田本人邮件沟通以及自己尝试,我知道了它们的编码方式。我会在接下来的步骤中说明。
(b2) 打完后,下载牌谱(参考1.(a)(b)),获取种子,base64解码,然后表示成16进制,不含0x,其中abcdef小写。再encode成bytes类型。至此,“乱数種”已经编码完成了。
1
seed = bytes(hex(int.from_bytes(base64.b64decode(seed_text), byteorder='big'))[2:], encoding='utf-8')
接下来我们获取“座席並べ替え情報”。要想获取这个情报,我们必须先知道角田是如何安排座位的。
角田分配座位的方法:根据四个玩家的名字的字典序升序,将玩家分别编号为0、1、2、3。角田事先确定这场比赛的座位安排为“xyzw”,其中x、y、z、w均为0到3的整数且不重复。意思是:玩家x东起,玩家y南起,玩家z西起,玩家w北起。
在打完段位后,我们可以从四个玩家的名字和他们实际的东南西北起,来逆推出这个“xyzw”。接下来我们来说明如何逆推出“xyzw”的值。
在牌谱中获取三个玩家的名字(四麻为四个玩家)。玩家名字在牌谱文件的UN tag里。
n0是东起玩家名,n1是南起玩家名,以此类推。例如我刚打的三般东喰赤的牌谱:<UN n0="%E3%81%A1%E3%82%83%E3%81%84%E3%81%BE%E3%81%99%E3%82%93%E3%81%93" n1="%E3%82%A2%E3%82%B0%E3%83%A2%E3%83%B3" n2="%4E%6F%4E%61%6D%65" n3="" dan="7,2,0,0" rate="1401.66,1569.12,1500.00,1500.00" sx="M,M,M,C"/>对玩家名进行url unquote,我们得到真正的名字:
n0='ちゃいますんこ', n1='アグモン', n2='NoName'将名字进行字典序升序排序,得到
['NoName', 'ちゃいますんこ', 'アグモン']根据角田分配座位的方法,NoName为玩家0,ちゃいますんこ为玩家1,アグモン为玩家2,三麻没有玩家3。这场比赛实际上玩家1东起,玩家2南起,玩家0西起,一个不存在的玩家3北起。于是我们可以推出“xyzw”=“1203”。我们想要知道的“座席並べ替え情報”就等于
b'1203'。1
seats = b'1203'
知道了“座席並べ替え情報”和“乱数種”,我们就可以计算hash了。直接把它们拼接起来再hash即可:
运行结果为1
2source = seat + seed
print(hashlib.sha512(source).hexdigest())与角田的工具的运行结果相同。1
9d268e0153446c7c238e12a110563b8decb95695d0dfe60dd3110e2323f9ce3ef5cf22cd1390564dbb7301572d554525fa772a2ca45f56e7167cb4c2d0139a00
- 打一把段位。在预约之前,打开https://tenhou.net/stat/rand/,根据我们要打的规则来点击对应的“表示”。如果我们打算打“三般东喰赤”,就点击红圈圈出来的“表示”。
因此天凤做到了:
- 一旦mtLocal的种子定下来,整场比赛每一小局的牌山都定下来了。而mtLocal的种子(的hash)在对局前就已经公开。也就是说,在比赛前,每一局的牌山早已确定,天凤的牌山不是“量子牌山”,角田无法在对局中篡改牌山。
- 在一桌四个人(三麻是三个人)匹配完成之后,角田无法随意将他们安排座位(谁东起谁南起),而是只能按照事先确定的席顺来安排座位。
也有以下不足之处:
玩家无法检验角田有没有故意选择牌山。虽然由于牌山生成算法是固定的且中间有hash步骤,角田不能为所欲为地生成奇葩牌山,但是角田可以在比赛前对mtLocal的种子进行选择。一个mtLocal的种子对应了一场比赛的所有小局的牌山,角田可以先看看这个种子生成的牌山是啥样的,然后决定用不用这个种子。席顺也是。
牌山の生成方法を完全公開にする予定です。
公開する情報は「配山の生成手法」と「乱数シード」になります。
これによって
1.作為的に配牌を選択していない
2.特定の局面で山を操作していない
ことが牌譜と対戦ログから検証可能になります。
※現状でも2.は検証可能です。
角田的博客中提到了“※現状でも2.は検証可能です”,也就是说“1.没有故意选择配牌”这点玩家无法验证。但是,即使角田故意选择了牌山,也很难给某个特定的玩家(比如氪金玩家)好牌、某个特定的玩家烂牌,因为mtLocal的种子、席顺是在对局前,甚至可能在玩家预约前、登录前就确定的。
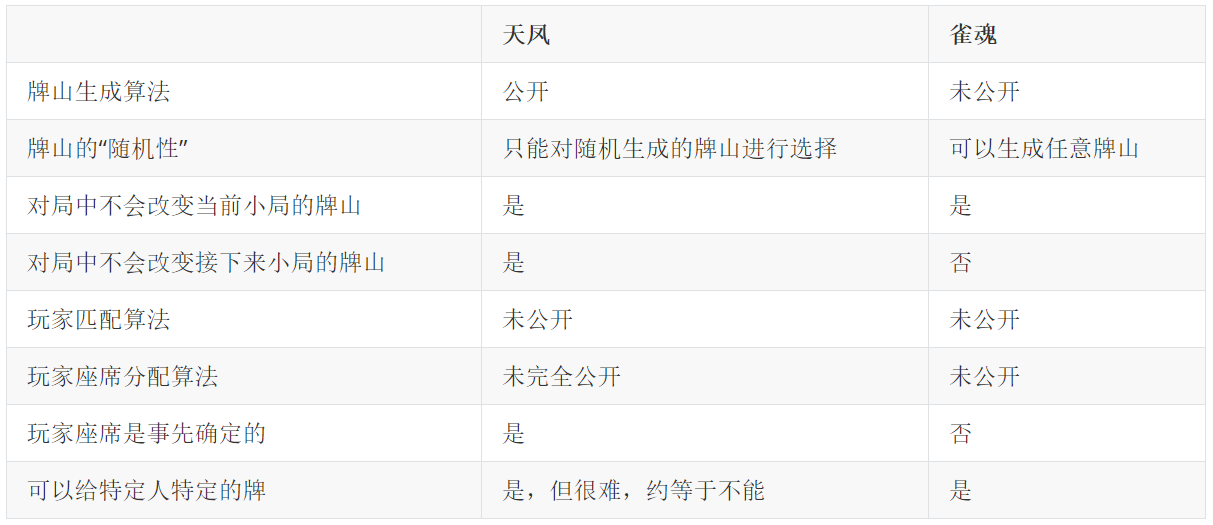
结论以及和雀魂的对比
天凤公开了牌山生成算法,在对局开始前公开了座位安排和这一场比赛使用的随机数种子的hash,在对局结束后在牌谱中公开了这一场比赛使用的随机数种子。因此席顺和这一场比赛所有小局的牌山早已确定。
雀魂只在每一小局开始时公开了该小局的牌山(不含四家起手的配牌)的MD5,其他均未公开。因此只能确定雀魂不会在对局中改变当前小局的牌山,其他均无法确定。
下表是“以最坏的恶意来揣测”天凤与雀魂,即对于玩家无法验证的事情均认为可以做。
写给结果论者
天凤这样的牌山生成和座位安排方法会导致发生一些有趣的事情。以下场景均有可能发生。
你东起,东一局其他三家立直,最后一巡你纠结要不要日一张牌形听,最后缩了,-3000。东二局下家上庄,天和四暗刻飞三家,自己吃4。如果当初自己日出了那张牌形听连庄,自己就会在东一局一本场天和四暗刻吃1。
有一次你突然想用NoName打一把。用NoName登上天凤,看见“四般南喰 3 :
0”,于是预约开打。其他三名玩家分别叫“Lemon”、“Orange”、“Peach”。你东起,东一天和四暗刻飞三家吃1。你觉得浪费了pt很可惜,使用时光机回到了登录前,用自己的号“RiJT”登录,看见“四般南喰
3 :
0”,于是预约开打。其他三名玩家分别叫“Orange”、“Lemon”、“Peach”。这时你发现不对劲,自己的ID激怒了角田,他安排你北起了。Orange东起,东一天和四暗刻飞三家吃1,你北起吃4。
参考资料
オンライン対戦麻雀 天鳳 / 牌山乱数 (tenhou.net)
玩物丧志(天凤麻雀洗牌代码) - 畅畅1 - 博客园 (cnblogs.com)
www.math.sci.hiroshima-u.ac.jp/m-mat/MT/MT2002/CODES/mt19937ar.c (hiroshima-u.ac.jp)
附录
从牌谱文件生成牌山
1 | #!/usr/bin/python3 |